This is a mix of real and fake echocardiograms, can you tell which is which ?
Hover a video to see whether it's an original sample, a factual generated sample or a counterfactual generated sample. You can also click this to tranform the mosaic into a game where you have to guess whether a sample is real or not.
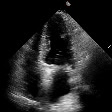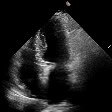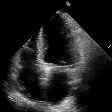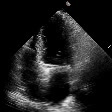
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Original
Score: 0/0 (0%)